Projects
GPU homelab server
Built a minimalistic homelab mATX-sized server with NVIDIA GPU, Xeon CPU and REG ECC RAM. Proxmox VE and GPU-enabled Docker containers. The server is used as a staging environment for Docker containers for GPU-accelerated apps, for running homelab VMs, running inference on models that require 24GB of VRAM, running training/inference code that requires CUDA v.11-12, rendering videos on CPU and GPU, code compilation.
GPU telemetry
Set up a GPU telemetry system for the cluster. Each node has a docker container with DCGM-Exporter that is leveraging NVIDIA Data Center GPU Manager (DCGM) and collects and exposes GPU metrics to Prometheus. Grafana uses this instance of Prometheus as the data source to visualize the GPU metrics. The data is used to monitor GPU compute load, temperature, power consumption, and memory usage.
Shared GPU resource allocation optimization
To achieve even more efficient compute resource utilization within Proxmox Virtual Environment, moved code execution from virtual machines to LXC. NVIDIA GPU and Infiniband adapters are passed to unprivileged containers, while for trusted environments privileged containers with GPU, cephFS through host bind mounts, and FUSE (for flexibility of mounting data sources) are used. This way, while keeping a sufficient degree of isolation for access convenience and security, the compute resources of a server are flexibly shared between research teams, achieving a higher utilization rate of the GPU and compute.
Prometheus
Set up docker environment in an LXC, added Portainer for easy management. Deployed dockerized Prometheus for metrics collection from CEPH cluster, and Grafana for visualization. The data is used to monitor CEPH performance and to predict future storage needs.
GPU Laptop for Data Science
Setting up a Lenovo laptop with NVIDIA GPU for Data Science. Ubuntu, LUKS full disk encryption, hibernation to S4, QEMU GPU passthrough to Ubuntu/Windows guests, CUDA/cuDNN in conda environments, Jupyter Lab, VSCode. The laptop is used for deep learning, data analysis, data engineering, and software development.
DIY CDROM emulator
Hardware CDROM emulator for ISO images using a Raspberry Pi Zero W

DIY IP KVM
Built a custom IP KVM using Raspberry Pi.

On-premise GPU cluster
Built on-premise multi-node multi-GPU hyperconverged cluster. Inter-node links are made with 10GbE fiber optics in LACP bonds and 200G Nvidia InfiniBand. Proxmox VE is used as the hypervisor. HDD/SSD storage connected through HBA in IT mode, CEPH with RBD erasure coding pools is used as the storage backend, cephfs mounted in VMs. Federated identity management with FreeIPA. GPUs are accessed using PCIe passthrough within Ubuntu VMs. The cluster is used for training deep learning models, and also for other tasks such as data engineering and data analysis. Hyper-converged infrastructure was chosen to reduce complexity, lower the total cost of ownership, and to increase flexibility and scalability. Increased flexibility of resource allocation leads to more efficient hardware utilization.
DL training process optimization
Identified a performance bottleneck in the training process, resolved it by integrating the Lightning Memory-Mapped Database into the dataloader class of the existing codebase, and moving training data to an SSD RAID. This led to faster preprocessing which in turn led to higher GPU compute utilization and faster training. What is LMDB.
Personal webpage
This website, built with React, Bootstrap, and Vite. GitHub Repository
Chinese word embedding
Helped to do the deep learning and data cleaning part of a research project. Trained embedding models from zero on different corpuses using original glove code and gensim word2vec. Different approaches to tokenization (hanlp, pkuseg, jieba), including using GPU. Several models with different vector dimensions were explored. The models were trained on a GPU server, and then used to calculate similarity between certain sets of words using cosine distance.
Audio classification
Applied research project. Audio classification task for speaker recognition. Trained a model using Pytorch, experiment tracking and visualizations with mlflow, deployed online with backend using ONNX runtime and FastAPI, frontend using a React webapp with Vite constructor and bootstrap5 css.
Speaker diarization pipeline
To prepare audio data for deep learning, I created a pipeline that uses NVIDIA NeMo to do speaker diarization, and then splits the audio into segments based on the diarization result.
On-premise GPU server
Set up a multi-GPU server with baremetal Ubuntu 22.04, mdadm RAIDs, backups. Installed and configured Nvidia drivers, CUDA/cudnn, user environments and rights management, conda environments with jupyter lab, SSH/RDP remote access.
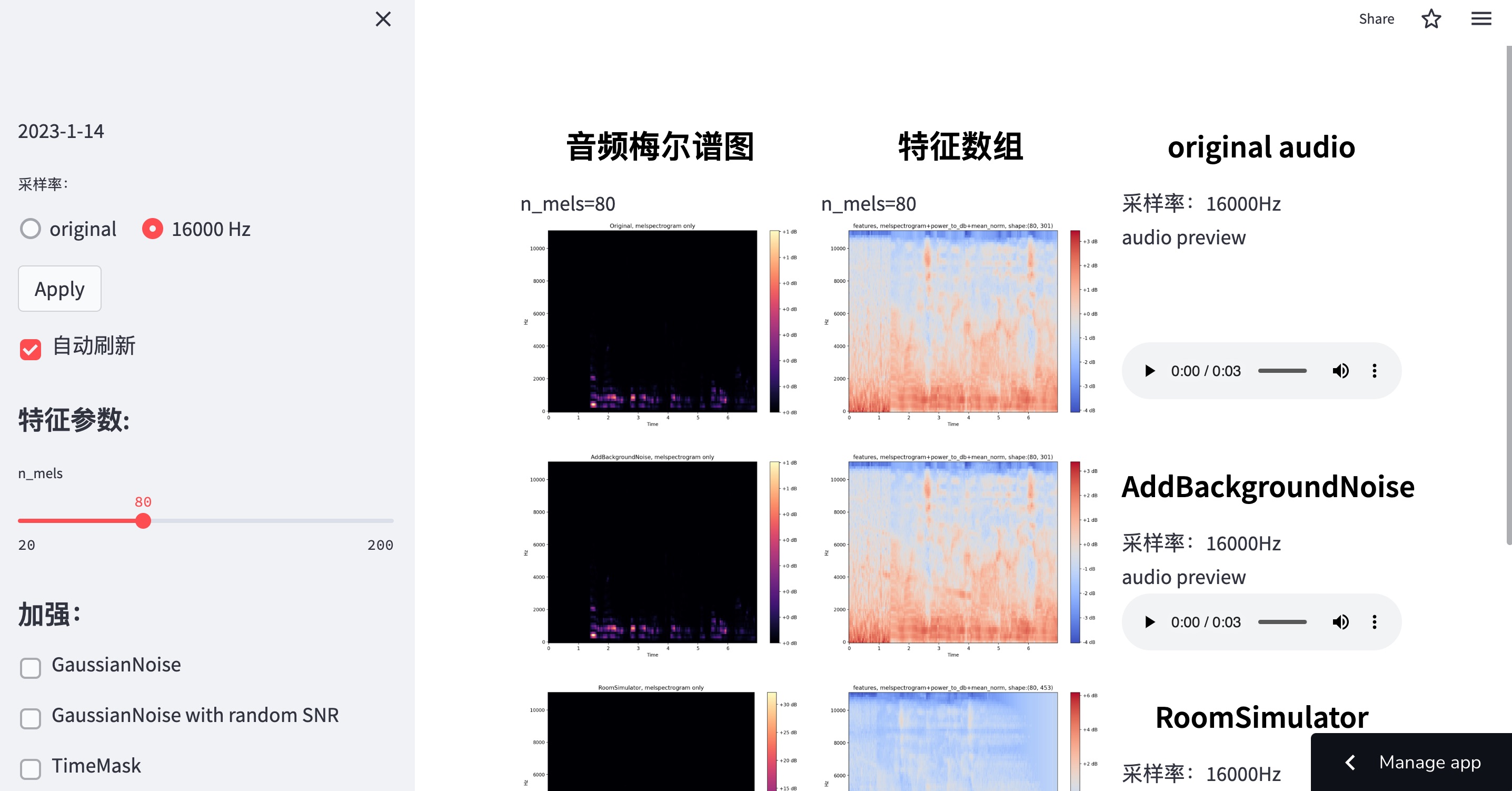
Deep learning audio feature visualization
An improved version of audio-transformation-visualization app that visualizes features of an audio file (melspectrogram) with added augmentation, deployed on streamlit cloud service. The changes I made to the app: added features that I use in my deep learning model, added the noise bank from MUSAN to preview noise augmentation result. The visualized array is what would be the input data for the neural network. Data augmentation is supposed to increase robustness of the model, and also reduce overfitting during training, so I believe the visualization of what the NN would get is important. Streamlit App
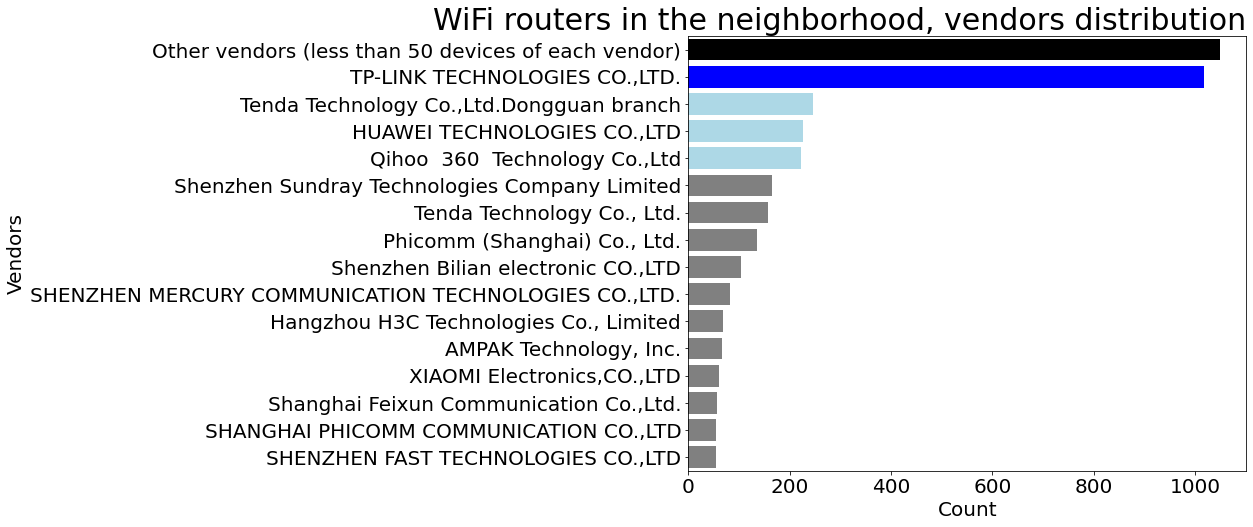
Data gathering and generating insights
A unique dataset was created by logging real life WiFi APs broadcast in a certain area. Used Python to generate insights from the data, plot WiFi APs on the map, do quantitative analysis of the hardware (including vendor distribution analysis, by cross-linking with another dataset). GitHub Repository
Machine learning
Applied research project as a part of the MA thesis: machine learning model for Mandarin Chinese tones pronunciation evaluation for second language learners.
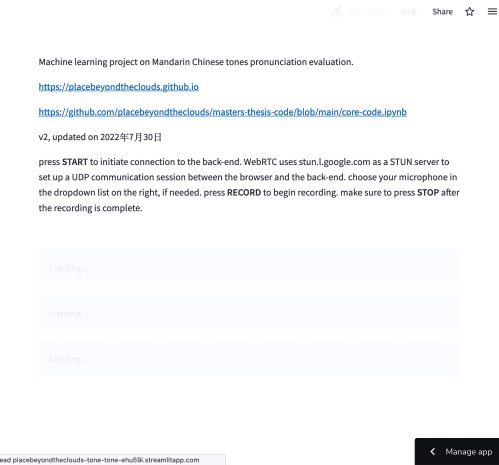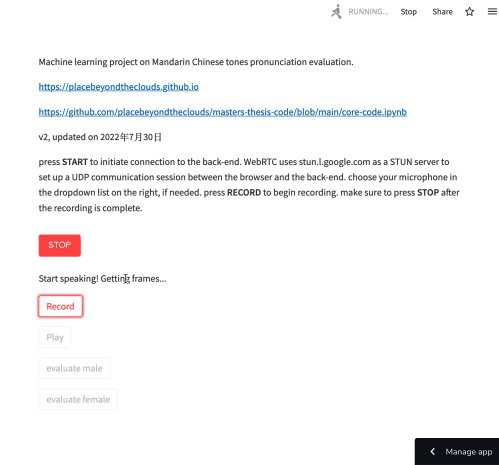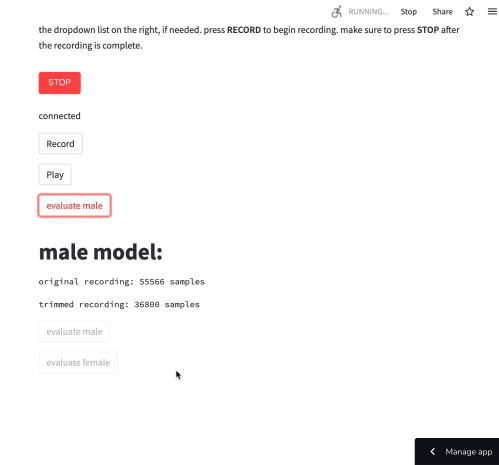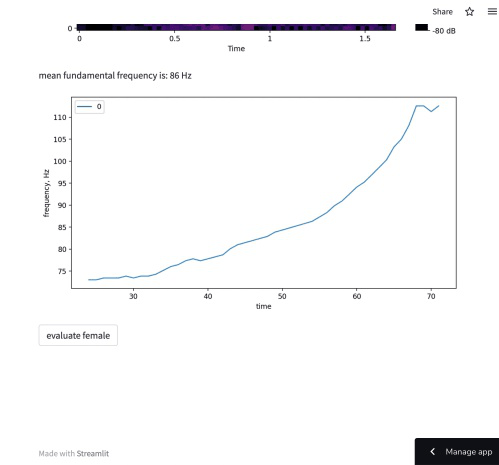
Data analysis
Interactive report on the dataset for the thesis project. It takes some time to get the dynos up and running, so there is a delay about half a minute between requesting the link and before the page loads. Online webapp, version 2:
Streamlit: Link Preview, version 1:
