项目
GPU 家庭实验室服务器
配置了一台 带有 NVIDIA 显卡、至强处理器 和 REG ECC 内存的极简家庭实验室 mATX 小型服务器。Proxmox VE 和支持 GPU 的 Docker 容器。该服务器用作显卡加速应用程序的暂存环境,用于运行家庭实验室虚拟机,运行需要 24GB VRAM 的模型推理,运行需要 CUDA 11-12版本的训练或推理代码,CPU 和 GPU 上的视频渲染,代码编译。
GPU 遥测
为集群设置了 GPU 遥测系统。每个节点都有一个 docker 容器,其中包含 DCGM-Exporter,利用 NVIDIA 数据中心 GPU 管理器(DCGM)收集和暴露 GPU 指标给 Prometheus。Grafana 使用此 Prometheus 实例作为数据源来可视化 GPU 指标。这些数据用于监控 GPU 计算负载、温度、功耗和内存使用情况。
共享 GPU 资源分配优化
为了在 Proxmox 虚拟环境中更高效地利用计算资源,将代码执行从虚拟机转移到 LXC。NVIDIA 显卡和 Infiniband 网卡被传递给非特权容器,而对于信任高的环境,使用了具有 GPU 支持、通过主机绑定挂载的 cephFS 以及 FUSE(灵活地挂载数据源)的特权容器。这样一来,即使考虑到对访问便利性和安全性的需求,我们仍可以灵活地将服务器计算资源分配给研究团队,从而实现 GPU 和计算资源的更高利用率。
Prometheus
在 LXC 上安装了 docker 环境,添加了 Portainer 以便于管理。部署了 docker 化的 Prometheus 用于从 CEPH 集群收集指标,Grafana 用于可视化。这些数据用于监控 CEPH 性能并预测未来的存储需求。
数据科学 GPU 笔记本
为数据科学设置了一台联想笔记本电脑,配备了 NVIDIA GPU。 Ubuntu,LUKS 全盘加密,休眠到 S4,QEMU GPU 直通到 Ubuntu/Windows 客户机,conda 环境中的 CUDA/cuDNN,Jupyter Lab,VSCode。笔记本电脑用于深度学习,数据分析,数据工程和软件开发。
自制CDROM模拟器
使用树莓派 Zero W 的硬件CDROM模拟器(用于ISO镜像)

DIY IP KVM

本地 GPU 集群
搭建了本地多节点多 GPU 超融合集群。节点间连接使用 10GbE 光纤 LACP 绑定和 200G Nvidia InfiniBand。Proxmox VE 主机。HDD/SSD 存储通过 HBA 以 IT 模式连接,CEPH 使用 RBD 上的 EC 池作为存储后端,cephfs 挂载在 VM 中。使用 FreeIPA 进行联合身份管理。GPU 通过 PCIe 直通在 Ubuntu 虚拟机中访问。集群用于训练深度学习模型,以及其他任务,如数据工程和数据分析。选择超融合基础设施是为了降低复杂性,降低总体拥有成本,并提高灵活性和可扩展性。增加资源分配的灵活性导致了更高的硬件利用率。
深度学习训练流程优化
在训练流程中发现了性能瓶颈,通过将 Lightning Memory-Mapped Database 集成到现有代码库的 dataloader 类中,并将训练数据移动到 SSD RAID 中来解决了这个问题。这导致了更快的预处理,从而导致了更高的 GPU 计算利用率和更快的训练。什么是 LMDB。
个人网站
这个网站,使用 React,Bootstrap 和 Vite 构建。 GitHub
中文词向量
协助完成研究项目的深度学习和数据清洗部分。使用原始 glove 代码和 gensim word2vec 在不同的语料库上从零开始训练嵌入模型。尝试了不同的分词方法(hanlp,pkuseg,jieba),包括使用 GPU。探索了几个不同维度的模型。模型在 GPU 服务器上训练,然后使用余弦距离计算一些词组之间的相似度。
音频分类
应用研究项目。说话人识别的音频分类任务。使用 Pytorch 训练模型,使用 mlflow 进行实验跟踪和可视化,使用 ONNX runtime 和 FastAPI 部署在线,使用 React webapp 和 Vite 构建和 bootstrap5 css 构建前端。
说话人分离流程
为了准备深度学习的音频数据,我创建了一个流程,使用 NVIDIA NeMo 进行说话人分离,然后根据分离结果将音频分割成片段。
本地 GPU 服务器
使用裸金属 Ubuntu 22.04,mdadm RAID,备份设置多 GPU 服务器。安装和配置 Nvidia drivers,CUDA/cudnn,用户环境和权限管理,conda 环境和 jupyter lab,SSH/RDP 远程访问。
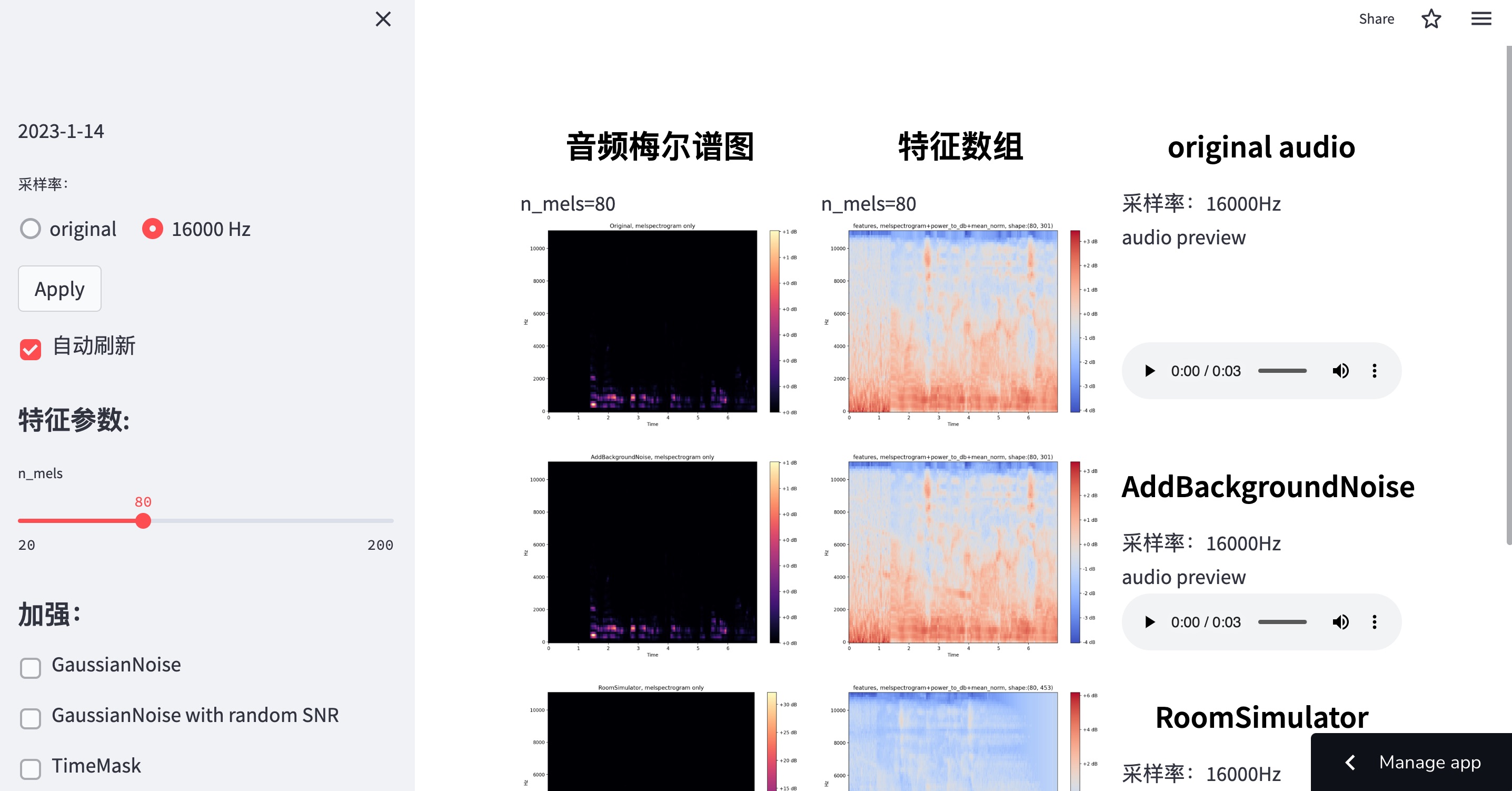
音频特征可视化
改进版本 用于可视化音频文件的特征(melspectrogram),在 streamlit 云服务上部署。我对应用程序所做的更改:添加了我在深度学习模型中使用的特性,添加了 MUSAN 的噪声库以预览噪声增强结果。可视化的数组是神经网络的输入数据。数据增强应该增加模型的鲁棒性,同时减少训练过程中的过拟合,因此我认为神经网络将获得的可视化是重要的。 预观
数据采集和分析
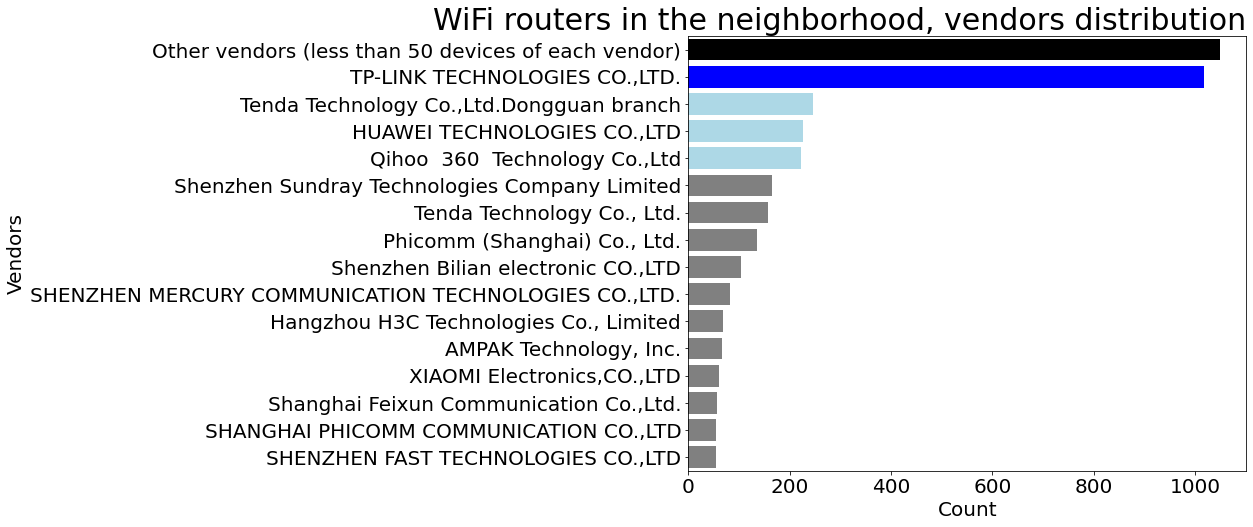
搜索某一个地方的 WiFi 传播建了数据库,对数据进行了分析和报告,包括对无线设备品牌的分配做了定量分析。Python 代码在 github 开发。 GitHub
机器学习
应用研究项目,硕士毕业论文的一部分。语音分类任务,测评第二语言学习者中文声调发音。
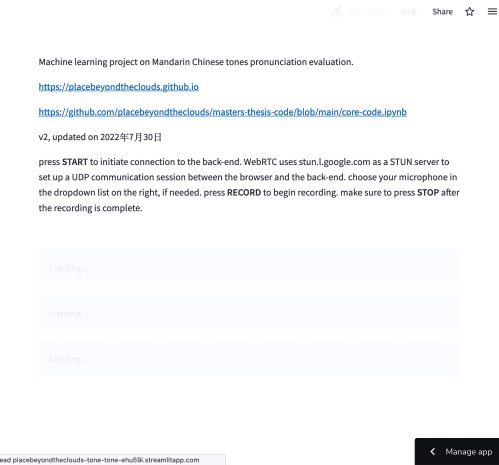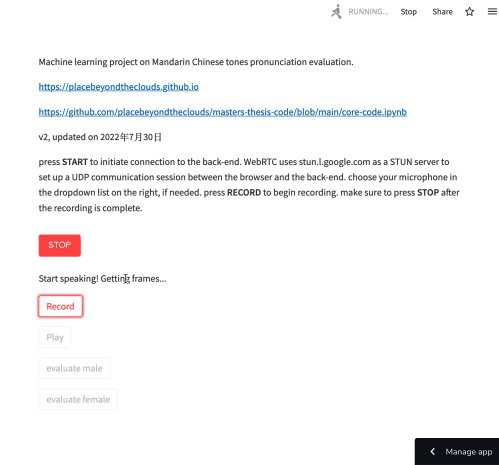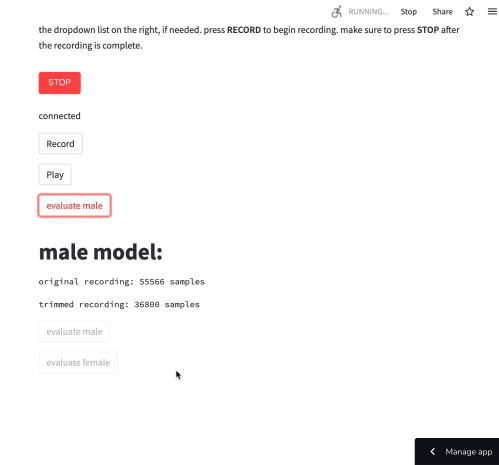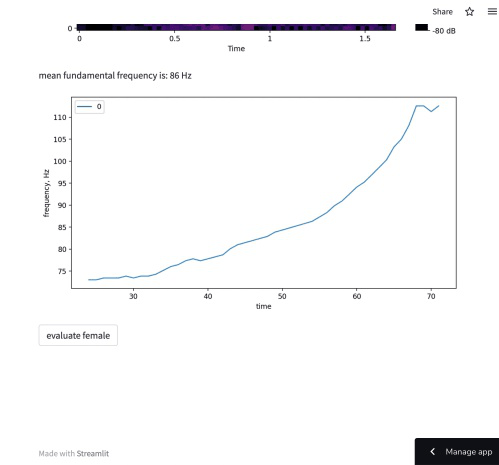
数据分析
普通话语料库分析,交互报告。服务器需要一段时间才启动。网页版应用,第 2 版本
- Streamlit: 链接
